|
 |
 |
 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 한글과 정보화 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
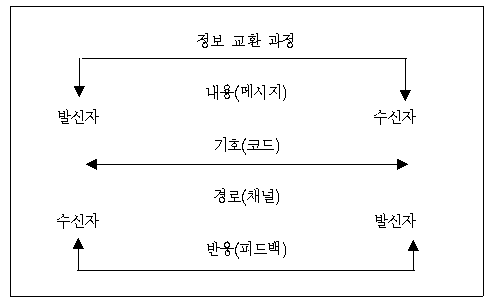
| 이병운∙부산대학교 국어교육과 교수 1. 머리말 통계청이 최근 발표한 ‘통계로 본 세계 속의 한국1)’ 에서 지난해 한국의 국내 총생산(GDP)은 세계 12위에 올랐고, 일인당 국민 총소득(GNI)은 16,291달러로 세계 29위에 올랐다. 이밖에도 평균 수명, 성인의 문자 해득률, 취학률 등을 기초로 한 인간 개발 지수에서는 세계 28위에 속했다. 또한 선박 건조량은 세계 1위, 자동차 생산량은 세계 5위, 철강 생산량은 세계 7위에 올랐다. 이와 아울러 2000년 이후 무선 이동 전화가 일반화되어 2004년 가입자 수는 1000명당 758명이고, 1999년에 초고속 인터넷 체제가 시작되어 2004년 인터넷 가입자 수는 100명당 66명으로 세계 3위가 되었다.그런데 이러한 세계 순위보다 더 중요한 것은 한국의 경제 성장 속도이다. 1953년에 일인당 국민 소득이 67달러에 불과하던 것이, 2005년에 16,291달러로 50년 만에 243배로 증가하였고, 국내 총생산도 1953년에 13억 달러에서 2005년에 7,875억 달러로 되어, 50년 만에 605.8배가 증가한 것이다. 30여 년간의 일제의 수탈과, 3년간 치른 6·25라는 전쟁의 폐허 상황에서 이러한 성과를 이루었으니 대단한 결과가 아닐 수 없다. 앨빈 토플러(1981)가 말한 제2의 물결이 서양에서는 300년이나 걸린 시간을, 우리는 30∼40년 만에 이루어 낸 것이다. 이러한 경제 성장의 속도는 세계에서 가장 빠른 것으로 인정되고 있다. 물론 최근 중국과 인도가 급속도로 발전하고 있어 이러한 기록이 깨어질지 모르겠지만, 지금까지는 한국이 가장 빠른 성장을 한 것임에 틀림없다. 우리의 놀라운 성장 속도는 물적 자원이 거의 없는 실정에서 가난을 벗어나겠다는 국민들의 의지와 노력, 정부의 치밀한 경제 계획의 결과였다. 그러나 무엇보다 이러한 결과를 가져온 데는 학교 공교육의 역할이 컸다고 할 수 있다. 구한말을 거치며 신분 제도가 철폐됨에 따라 국민들의 신분 상승과 경제적 부에 대한 욕구가 교육에 대한 열정과 수요로 나타났던 것이고, 이에 따라 취학률이 급상승하였던 것이다.2) 이와 아울러 한국도 1990년 후반에는 제3의 물결인 정보화 시대가 본격적으로 접어들면서, 거의 모든 정보를 인터넷과 무선 전화로 교환하게 되었다. 이런 정보화 부문에 한국이 급속한 발전을 하게 된 것은 한국이 최초로 상용화한 코드 분할 방식(CDMA)의 무선 전화 기술과, 최첨단의 반도체 기술 등 정보 기술의 발달과, 아파트 중심의 주거 양식과 활동적인 한국인의 성격과 관련이 있다 하겠다. 그러나 무엇보다 정보화 시대로의 이행을 순조롭게 한 것은 정보 교환의 코드인 문자의 특성에 있다 하겠다. 앨빈 토플러(1981)가 ‘제3의 물결 시대에는 무엇보다 정보가 자유로이 흐르는 사회는 발달하고 그렇지 못한 사회는 쇠퇴한다’라고 예언하였듯이3), 한국이 80년대 후반에 민주화가 되고, 우리가 정보 교환에 사용하는 코드(기호)인 ‘한글’이 가지고 있는 과학성과 용이성이 정보화의 발전에 박차를 가했다고 볼 수 있다. <그림 1>에서 보듯이 정보를 교환하기 위해서 사용하는 코드는 일반적으로 언어 기호를 사용한다. 이 언어 기호에는 음성 언어와 문자 언어가 있지만, 직접 대면하지 않는 상황에서 대량으로 전달하는 기호는 대부분 문자 언어이다. 현대의 정보 교환에 사용하는 언어 기호에서도 문자(언어)가 음성(언어)보다 많고, 그 사용량이 앞으로도 더욱 증가할 것이다. 앨빈 토플러(2006; 165∼166)에 의하면 미국인들이 평생 동안 접하는 지식의 총량을 두뇌 내부에 저장하는 6기가(109, 10억)바이트와 두뇌 외부에 저장된 지식을 합하면 1만 2,000페타(1015, 1,000조)바이트의 정보가 존재한다고 보았다. 그런데 이들 대부분의 정보가 문자 기호로 전달되었으니, 우리의 정보 혁명에서 한글이 담당한 역할은 아주 큰 것이다. 우리의 뛰어난 정보 기술과, 우리의 독특한 주택 문화와 적극적인 성격 이외에도 정보 교환의 기호로써 한글이 한국의 경제성장과 정보화에 얼마나 큰 기여를 하였는가를 살펴보는 것도 한글날을 맞이하여 의미 있는 일이 될 것이다.
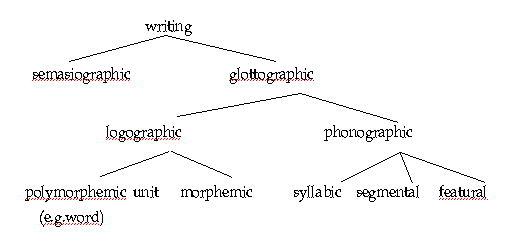
2. 문자의 발달 단계와 분류 세계에 많은 언어가 있지만4) 사용하는 문자는 크게 세 계통이 있다. 그 가운데 가장 영향력이 큰 것은 이집트 문자에서 여러 문자로 발전한 계통이다. 이집트 문자는 셈계의 페니키아 문자로 발달하고, 다시 그리스 문자로, 그리고 로마 문자로 발달하였는데, 대부분의 유럽 문자가 이 계통에 속한다. 이 계통의 알람 문자5) 는 동쪽으로 전파되어 아시아의 몽골 문자, 돌궐 문자, 위구르 문자, 만주 문자로 변형되기도 하였다. 또한 알람 문자의 한 계통은 티베트 문자, 버마 문자, 타이 문자로 이어졌고, 티베트 문자와 파스파 문자로도 변형되었다. 또 한 계통은 수메르의 쐐기 문자인데 이는 바빌로니아 문자, 아시리아 문자, 히타이트 문자로 이어졌다. 마지막 한 계통이 중국의 한자인데 이에서 서하 문자6), 거란 문자, 여진 문자, 일본의 가나 문자가 생겼다.문자는 음성 언어가 가진 한계(시간, 공간, 기억력)를 보완하기 위해 만든 시각 기호이다. 우리가 인류 역사를 구분할 때, 문자로 기록한 이후의 시대를 역사 시대라 하고, 기록이 없던 그 이전의 시대를 선사 시대라 하는 것처럼, 문자의 발명과 기록은 불분명한 혼돈과 암흑의 세계에서 우리를 명확한 질서와 명정(明淨)의 세계로 인도했다. 그뿐 아니라 문자의 발명과 기록은 인류 정보의 축적을 가능하게 하였고, 나아가 인류 문화의 축적을 가능하게 한 것이다. 그러므로 우리가 영위하고 구가하는 오늘의 인류 문화도 따지고 보면, 문자의 발명으로 가능하였다고 할 수 있다. 위에 언급한 많은 문자들은 다양한 발달 과정을 거쳤는데, 이를 샘슨(1985)에서는 <그림 2>와 같이 분류하고 있다. 문자에 앞선 단계는 사람의 생각과 욕구를 나타내었던 그림의 단계다. 문자가 없던 원시 시대의 동굴 벽화나 암벽화가 이에 해당할 것이다. 그림과 문자를 구분하는 기준은 문자에 비해 그림은 똑같은 의미를 상대방에게 주지 않는다는 것이다. 어떤 그림에 대하여, 공통적으로 전달되는 관습적 의미도 있지만, 비평가와 감상자가 화가의 의도를 정확하게 알 수는 없다.
그러나 문자는 그 체계를 알면 그 의미는 같게 전달된다. 이러한 그림과 문자의 중간 단계이며 문자의 초기단계가 그림 문자7) (semasiographic)이다. 이는 완전한 표기 체계(writing system)는 아니지만 문자의 초기 단계로서, 전달하려는 공통된 의미는 있지만, 이에 대응하는 공통된 언어 단위는 없다. 그러므로 의사소통은 되지만 이를 소리 내어 읽을 수는 없다. 요즘 사용하는 도로 교통 표지, 운동 경기장 등에 사용하는 여러 안내표지나, 인터넷에서 사용하는 이모티콘 등이 그림문자의 일종이다. 본질적 문자는 음성언어의 어떤 단위에 대응하느냐에 따라 분류된다. 언어에서 의미를 가진 단위, 곧 1차 분절로 얻어지는 단어, 형태소 같은 의미 단위에 대응하느냐, 2차 분절로 얻어지는 음절, 음소 등의 음성 단위에 대응하느냐에 따라 표의 문자와 표음 문자로 나뉜다. 그래서 단어나 형태소 같이 의미를 가진 언어 단위에 대응하는 문자를 표의 문자(logographic)라 하고, 음절이나 음소 같이 음성 단위에 대응하는 문자를 표음 문자(phonographic)라 한다. 표의 문자에는 한자나, 이집트 문자 같은 단어 문자, 또는 형태소 문자8) 가 있고, 표음문자에는 음절 문자, 음소 문자, 자질 문자가 있다. 음절 문자(syllabic)에는 페니키아 문자, 일본의 가나 문자, 훈민정음 창제 이전의 차자 표기9) 에 사용된 문자 등이 해당하는데, 음절 단위에 하나의 문자가 대응한다. 음소 문자(segmental)에는 로마자, 한글 등이 해당하는데, 음소 단위에 하나의 문자가 대응한다. 샘슨 교수가 분류한 문자 체계 가운데 독특한 것이 자질 문자(featural)인데 이것은 그가 오로지 한글을 위해 새로이 분류한 것으로, 그는 장(7장)을 독립해서 한글의 제자 원리와 표기법에 대해 자세히 설명하고 있다. 이 글에서는 4장에서 설명하기로 한다. 3. 우수한 문자와 언어의 특성 문자의 발달 단계에서도 본 것처럼 문자는 그림 문자에서 표의 문자로 다시 표음 문자로 발달해 왔다. 표음 문자는 다시 음절 문자에서 음소 문자로 발달해 왔다. 이렇게 발달해 온 과정은 문자의 우수성과 관련이 있다. 우수한 문자는 간결하고 쉬워야 한다. 문자가 간결하다는 것은 문자의 수가 적어야 하고 문자의 형상도 간단해야 한다. 또한 문자가 쉬우려면 체계적이어야 한다.한자나 이집트 문자 같은 단어 문자일 경우, 그 수는 단어의 수만큼이나 많아진다. 한자의 경우, 많게는 수 만 자나 되고, 문자의 형상(부수나 획수)도 복잡하기 짝이 없다. 그리하여 중국은 사회주의 혁명 후, 한자를 세 가지 부분에서 개혁을 하였다. 하나는 문자의 수를 줄이기 위해 같은 소리가 나는 한자를 같이 표기하였다. 이를 테면, ‘구름’ 雲 자와 ‘이를’ 云자를 云자로 같이 표기하고, ‘얼굴’ 面자와 ‘국수’ 麵자를 面자로 같이 표기한다. 이것을 변별하는 방법은 문맥과 상황에 따라 할 수밖에 없다. 필자가 중국 북경대학에 파견 교수로 있을 때, 식당 차림표의 음식 이름에 ‘얼굴’ 面자가 가득한 것을 보고 처음에 얼마나 놀랐는지 모른다. 또한 복잡하기 짝이 없는 부수와 획수를 간단하게 줄이고, 그것도 체계적으로 하였다는 것이다. ‘볕’ 陽자와 ‘그늘’ 陰자를 阳자와 阴자로 표기하는 방식이다. 그래서 중국의 간자체는 이미 표의 문자와 표음 문자의 성격을 모두 가지고 있어 표의 문자만은 아니다. 일본어에서 음절 문자인 가나 문자를 택한 것은 일본어의 음절 구조가 간단하고(CV 구조, C는 자음, V는 모음), 모음 수가 적기 때문에 가능하였다. 페니키아 어10) 는 모음의 수가 적고, 모음을 변별하는 기능이 없어 페니키아문자는 자음자만 쓰이는데, 읽을 때는 모음을 적당히 넣어11) 발음하는 음절 문자다. 이와 같이 음절 구조가 간단하거나 모음수가 적은 언어에서 음절 문자를 사용했다. 중국의 한자도 표의 문자이기도 하지만, 한 문자가 한 음절에 해당하는 음절 문자이기도 한데, 중국어 또한 음절 구조가 간단하고(CVC 구조), 모음 수도 적기 때문에 그러하다. 그러나 음절 구조가 복잡한 인도·유럽어나, 한국어에서는 음절 문자가 적합하지 않았다. 그래서 인도·유럽어의 하나인 그리스 어는 페니키아 어에 비해 모음 수도 많고 음절 구조도 복잡하기 때문에 페니키아 문자를 그대로 쓸 수 없기에12) 페니키아의 음절 문자를 음소 문자로 바꾼 것이다. 중세 한국어의 음절 구조도 복잡하기(; 酉時, CCCVCCC) 때문에 구결 같은 음절 문자로 표기하기에는 그 수가 많고 너무 복잡하여 세종은 음소 문자를 창제한 것이다. 이와 같이 문자는 표기하려는 음성 언어의 특성과 관련이 있고, 음성 언어의 단점을 보완하기 위해 만들어진 것이므로, 문자의 수가 많고 복잡하면 본래의 기능과 어긋난다. 이런 이유로 세계의 많은 문자는 표의 문자에서 표음 문자로, 그리고 표음 문자에서도 음절 문자에서 음소 문자로 발달한 것이다. 그것은 언어 단위에서 단어의 수보다 음절의 수가 적고, 음절의 수보다 음소의 수가 적기 때문에 적은 문자의 수로 언어를 표기하는 것이 가장 경제적이기 때문이다. 그러나 문자의 수가 단순히 적다고 해서 표기법이 이상적인 것은 아니다. 발신자의 의도를 수신자에게 효과적으로 전달하기 위해서, 문자는 간결성 이외에도 표의성이 있어야 한다. 중국어는 형태의 변화가 없는 고립어이고, 단어가 대부분 단음절어이므로, 문자가 다소 복잡하더라도 형태가 지닌 의미의 변별성이 있으면 그 뜻을 전달할 수 있어 표의성이 우수하다. 그래서 중국어는 동음어가 많지만, 한자의 모양을 달리하여 동음어를 변별할 수 있다는 장점이 있다. 표음 문자를 채택한 영어 표기법이나한국어 표기법에서도 표음 문자의 단점을 보완하기 위해 같은 소리이지만 표기를 달리하고 있다. 예를 들면 한국어 표기법에서 ‘낟, 낫, 낮, 낯, 낱’ 등이 음절말에서 모두 [낟]으로 발음되더라도 뜻을 구분하기 위하여 달리 표기하는 방식이나, 영어 표기법에서 같은 발음의 [najt]지만 ‘knight’와 ‘night’로 달리 표기하는 방식이 모두 표음문자의 단점을 보완하기 위한 것이다. 문자의 우수성에서 가장 중요한 것은 문자의 체계성이라 할 수 있다. 같은 음소 문자라도 변별성이 뛰어나고 체계성이 있어야 우수한 문자이다. 이러한 점에서 많은 외국의 언어학자들이 한글의 우수성을 칭찬하였다. 곧 샘슨(1985, 102) 교수의 인용에서 보이듯, 한글을 라이샤워(1958)에서는 ‘세계에서 가장 과학적인 표기 체계’라 했고, 포스(1964)에서도 ‘세계에서 가장 우수한 알파벳’이라고 극찬하였던 것이다. 샘슨 교수 자신도 문자 체계를 분류하면서 한글만을 위해 ‘자질 문자 체계’(featural writing system)를 따로 분류하였다. 4. 한글과 한국어 표기법의 특성 앞에서도 언급하였듯이 한글은 자질 문자이다. 사실 자질 문자라는 분류는 하나의 문자가 음성 자질에 대응한다는 의미가 아니라, 문자의 형상과 체계가 음성의 자질에 대응한다는 것이다.13) 한글에서 자음자의 음성 자질과 문자 체계를 정리하면 <표 1>과 같다. 한글의 자음자는 사물의 형상을 본뜨는 상형, 획을 더하여 만드는 가획, 만들어진 문자를 합하여 만드는 합성이라는 세 원리에 의해 만들었다.14) 먼저 기본자는 조음 방식과 조음 기관을 본뜬 상형의 원리에 의해 만들었다. 아래 <표 1>에서 보듯이 조음 위치에 따라 분류한 어금닛소리(牙音), 혓소리(舌音), 입술소리(脣音), 잇소리(齒音), 목구멍소리(喉音)에서 가장 약한 소리15) 를 기본음으로 하여 이것들의 조음 방법과 조음 기관의 모습을 상형하여 만든 것이다. 그런데 어금닛소리(牙音)에서 가장 약한 소리는 불청불탁음(不淸不濁音)인 /ŋ/을 기본음으로 하여야 했으나, 중국 음운학의 중고음에서 의모(疑母) /ŋ/과 유모(喩母) /j/ 16) 가 이미 홍무정운(洪武正韻) 같은 중국운서에서 서로 바뀌어 쓰이고 유모의 음가가 영성모(零聖母) /∅/로 쓰이어, 훈민정음(한글)의 제자 원리에서도 어금닛소릿자의 제자 시초를 불청불탁음 /ŋ/으로 잡지 않고, 전청음 /k/로 잡았다. 이에 영향을 받아 /ŋ/ 소릿자를 목구멍소리 /ɦ/ 소릿자 ‘ㅇ’에서 변형하여 ‘ᅌ’을 만든 것이다. 이것은 아래 <표 1>에서 보는 것처럼 전체적인 체계에서 어긋나게 되었다. 곧 자음자의 기본자는 모두 지속음의 자질을 가졌는데, 오직 어금닛소리에서만 전청음(예사소리)을 제자의 시초로 삼아 파열음인 것이다. 물론 잇소리에서도 전청음을 제자의 시초로 삼았지만 이는 지속음의 체계에는 어긋나지 않는다. 그런데 만일 /ŋ/을 ‘ㄱ’으로, /k/를 ‘⊐’으로, /kh/를 ‘∃’으로 만들었다면 완벽하게 체계에 맞은 문자가 되었을 것이다.
사실 /ŋ/과 /k/는 조음할 때, 혀의 모양은 꼭 같으나, /ŋ/은 목젖이 올라가 기류가 코로 나가고 /k/는 입으로 나가기 때문에 /ŋ/을 ‘ㄱ’자로 만들어도 무방하다. 그러면 기본자는 조음 방법과 조음 기관을 상형하여 만들고, 전청자(예사소릿자)는 기본자에 가획(1차)하여 만들고, 차청자(거센소릿자)는 전청자에 다시 가획(2차)하여 만드는 일관된 원리가 적용되었을 것이다. 전탁자(된소릿자)는 전청자를 옆으로 합성(병서)하여 만들고. 순경음자와 설경음자는 순음자와 설음자에 ‘ㅇ’을 아래로 합성(연서)하여 만드는 원리를 적용하였다. 결론적으로 기본자는 음성 자질이 지속 자질이고, 기본자에서 전청자로 만드는 1차 가획은 폐쇄 자질이며, 전청자에서 차청자로 만드는 2차 가획은 기식(氣息) 자질이며, 전청자를 합성하여 전탁자를 만드는 합성(병서)은 긴장 자질이며, 순음자에서 순경음자로 만드는 ‘ㅇ’의 합성은 마찰 자질과 유성 자질을 나타낸다고 볼 수 있다. 이 원리에 예외적인 문자는 ‘ㅇ→ᅌ’, ‘ㄷ→ㄹ’ ‘ㅅ→ㅿ’이 있다. 잇소리에서 가장 약한 소리는 불청불탁음인 /z/(ㅿ)이지만, 이 소리는 5음체계에도 포함되지 않고, 분포에도 제약이 있어, 전청음인 /s/(ㅅ)를 제자의 시초로 삼았다. 또한 전탁자는 전청자를 병서하여 만들었지만 목구멍소리에서 /ʔ/(ㆆ)은 소리가 깊어 잘 엉기지 않으므로 소리가 얕아 잘 엉기는 차청음자 ‘ㅎ’을 병서하여 만들었다. 모음자의 제자 원리도 상형, 합성, 가획이다. 한글을 창제하는 데 있어, 자음자는 중국운서의 성모(聲母) 분류인 오음(아음, 설음, 순음, 치음, 후음) 체계와 청탁(전청, 차청, 전탁, 불청불탁) 체계를 그대로 따랐지만, 모음자는 완전히 새로운 체계이다. 왜냐하면 중국 성운학의 체계에서는 음절을 성모와 운모(韻母 : 중성+종성)로 나누는 2분 체계이지만, 훈민정음에서는 음절을 오늘날과 같이 초성, 중성, 종성으로 3분하였던 것이다. 그러므로 오늘날의 모음에 해당하는 중성에 대한 분류를 완전히 새로이 해야 했다. 또한 종성은 초성의 위치적 변이음이라는 사실을 확인하고 종성자를 따로 만들지 않았다(終聲復用初聲). 이러한 초성과 종성이 환경에 따라 달라지는 변이음이라는 사실은 우리말의 연음 현상에서 확인된다. 곧 /달/이라는 낱말이 뒤에 모음으로 시작하는 조사 /이/와 결합하면 종성의 /ㄹ/이 /다리/와 같이 초성으로 되기도 한다는 사실을 확인할 수 있고, 종성에서는 [l]로 초성에서는 [ɾ]로 달리 나지만 같은 음소라는 사실을 확인하였던 것이다. 그리하여 초성자의 ‘ㄹ’을 설경음자 ‘ᄛ’로 만들 수는 있지만 사용하지는 않았다. 그래서 모든 종성자는 따로 만들지 않았던 것이다. 그러나 모음자(중성자)는 중국 음운학에 분류가 없으니, 완전히 새로 분류해야만 했던 것이다. 그래서 모음을 혀의 상태(舌縮, 舌小縮, 舌不縮), 소리의 깊이(聲深, 聲不深不淺, 聲淺), 입술의 모양(口中17), 口蹙, 口張)의 자질로 분류하였던 것이다. 먼저 기본음 /ʌ/, /ɨ/, /i/를 각각 아래 <표 2>처럼 <舌> 자질과 <聲> 자질로 나누어, <舌縮>, <聲深>자질을 양(陽)으로, <舌小縮>, <聲不深不淺>을 음(陰)으로, <舌不縮>, <聲淺>자질을 중(中)으로 해석하여 이에 상응하는 역리학적 대상을 ‘하늘’, ‘땅’, ‘사람’으로 삼고, 이를 추상적으로 상형하여 각각 「 · 」, 「ㅡ」, 「 l 」자로 만들었다. 두 번째, 초출자는 그 자질에 따라 <口蹙>자질은 「 ㅡ 」, <口張> 자질은 「 l 」로 하였고, <陽> 자질은 「 ㅡ 」의 위와, 「 l 」의 밖에 「 · 」을 합성하는 것으로, <陰> 자질은 「ㅡ」의 아래와, 「 l 」의 안에 합성하는 것으로 원리를 삼았다. 세 번째, 재출자는 <起於 l> 자질 곧 과도음 [j]를 「∸」, 「ㅣ・」, 「 」, 「 ·|」에 「 · 」를 가획하는 것으로 하였다. 그러므로 한글은 음성의 자질이 문자의 형상에 체계적으로 반영된 완벽한 자질 문자인 것이다. 세계 어느 나라 문자에 이러한 음성 자질이 문자의 형상에 체계적으로 반영된 문자가 있는가. 또한 모음자의 상형 방식도 이집트 문자나 한자처럼 사물의 형상을 그대로 본뜬 것이 아니라, 추상적으로 본뜬 것이다. 한국의 휴대 전화 제조 회사들은 이러한 원리를 적용하여 휴대 전화의 자판에 우리의 문자 40자(자음자 19자, 모음자 21자)를 쉽게 입력하도록 하였다. 곧 기본 자음자에다 <가획>하거나 <합성>하여 19개의 자음자를, 기본 모음자 세 개를 <합성>하는 원리를 적용하여 21개의 모음자를 어떤 문자보다도 빠르게 입력할 수 있게 한 것이다.
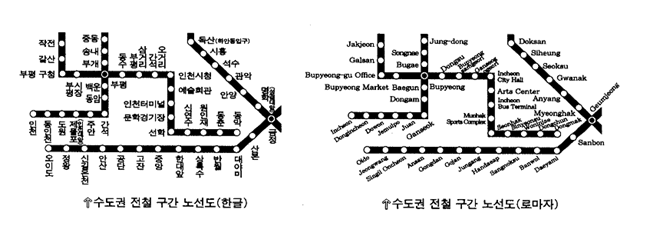
우리의 표기법은 독특하다. 곧 음소 문자이면서 로마자처럼 낱자를 옆으로 나열하는 것이 아니라, 초성자, 중성자, 종성자를 음절 단위로 모아서 표기한다는 것이다. 이러한 표기법은 한 때, 최초의 기계화 단계인 타자기에서 많은 문제점으로 등장하였다. 곧 음절 단위로 묶어서 쓰자니, 같은 ㄱ자도 모음자의 위에 올 때, 앞에 올 때, 그리고 받침에 올 때, 받침도 겹받침이 올 때와 홑받침이 올 때마다 문자의 모양이 다르니, 타자기의 자판이 3벌씩, 4벌씩으로 될 수밖에 없었다. 이러한 문제점 때문에 글자의 모양에 상관없이 2벌씩으로 하자는 방식도 있었다. 그러나 더 큰 문제는 전신을 보낼 때였다. 수동으로 치는 타자기는 키를 사용하여 느리고, 번거롭지만 그래도 타자가 가능했지만, 전신기는 3벌식, 4벌식으로 사용할 수 없었다. 그리하여 한때, 로마자처럼 한글 자모를 낱자로 분리하여 타자된 전보를 받던 시기도 있었다. 최현배18) 선생은 이를 안타까이 여겨 로마자를 흉내 낸 흘림체 한글체를 개발하기도 하였다. 더구나 최현배 선생은 음절 초에 오는 ‘ㅇ’은 무의미하니 없애자는 주장도 하였다. 그러나 문자입력기에서 받침으로 될 것과 초성자로 될 것을 구분하는 방법은 이응자 ‘ㅇ’이 있고 없고에 따라 결정된다. 곧 ‘솔이’와 ‘소리’를 구분하는 것은 ‘ㄹ’ 뒤 초성자에 이응이 있으면 종성자(솔)로, 이응이 없으면 초성자(리)로 배분되어 자동적으로 처리되는데, 만일 이 이응이 없다면 어떻게 처리할 것인가? 이 또한 세종대왕이 초성자로 이 이응자를 창제하였기에 가능한 것이 아닌가? 만일 현대처럼 음가가 없으니19), 제외한다면 이러한 한글 입력도 종성자와 초성자를 분리하는 특별한 기능을 추가하여만 위의 글자를 입력할 수 있을 것이다. 그러나 이러한 타자기의 문제도 컴퓨터의 한글입력기가 개발되고는 일시에 해결되었다. 어쩌면 세종대왕께서 500년 후의 컴퓨터 시대를 예상하였는지 모를 일이다. 5. 한국어 표기법과 다른 나라의 표기법 앞서도 설명하였지만, 로마자가 한글과 같은 음소 문자이지만, 한글이 만들어진 과정처럼 많은 학자가 일시에 집중적으로 연구하여 만든 것이 아니라, 수천 년의 변천 과정을 거쳐서 만들어졌기 때문에 로마자의 모양은 음성적으로 서로 관련이 없어 체계적이지도 못하고, 하나의 음소에 하나의 문자가 대응하지도 않는다. 예를 들면, 로마자의 p와 b, t와 d, k와 g가 문자 형상에서 유성과 무성이라는 음성적 관련이 있지도 않다. 또한 영어에서 사용하는 ‘a’라는 문자에 대응되는 음소가 10개 이상이나 되어 1음소 1문자가 대응하지도 않는다. 이것은 애초에 페니키아 문자에서 두음에 사용하던 자음자를 모음자로 전용하여 썼기 때문에 그러하다. 그리스인들은 페니키아 문자 가운데서 그리스 어 표기에 필요 없는 자음자를 모음자로 전용하였다. 그리하여 모음자가 5자밖에 되지 않았다. 그러나 현대 영어에서 단모음의 수가 10개가 넘고, 여기에다 중모음의 수를 합치면 더 많아진다. 그런데 모음자의 수는 5개밖에 없으니, 할 수 없이 한 문자로 여러 음소를 나타낼 수밖에 없다. 곧 로마자가 1음소에 1문자가 대응하지 않는 것은 애초에 모음자가 없었기 때문이다.그런데, 자음자에서도 이런 모순이 있다. 예를 들면 /k/라는 음소를 나타내는 문자는 ‘k, c, q, x’ 등이 있고, ‘x’라는 문자는 둘 이상의 음소[ks]를 표기하기도 한다. 그러므로 로마자를 사용하는 언어들은 사전에 발음 기호가 필요한 것이다. 미국인들의 방송 프로그램 중에 어떤 단어에 대한 철자를 알아맞히는 퀴즈 대회가 있다는 소릴 듣고, 그들의 문자 생활이 고단하다는 것을 느낄 수 있었다. 그러므로 이런 사회는 문자해득률에 있어서 우리와 많은 차이가 날 수밖에 없다. 그러나 정작 문제는 문자를 실제 운용하는 표기 체계인 표기법에 있다. 로마자 표기법은 왼쪽에서 오른쪽으로 알파벳을 나열하게 돼 있어 수직 방향의 아래로는 사용할 수 없다. 억지로 사용한다면 비스듬히 대각선 방향으로 사용할 수 있을 것이다. 더 큰 문제는 거리의 표지판이나, 교통 표지판 같은 제한된 공간에서 옆으로 길게 나열하는 로마자 표기법은 공간의 제약을 받기 때문에 문자를 작게 할 수밖에 없다. 그럴 경우, 이것을 멀리서 읽고서 식별하기는 아주 어렵다. 더구나, 인도·유럽어는 단어가 다음절어이어서 단어를 표기하려면 옆으로 길게 늘어질 수밖에 없다. 그러므로 낱자로 가로로만 쓰는 로마자 표기법은 공간의 제약을 많이 받을 수밖에 없다. 더구나 지도 같이 좁은 지면에 많은 지명을 표기해야 할 경우, 많은 제약을 받게 된다. 이러한 제약 때문에 로마자 표기법에서는 약어(acronym)가 발달한 것이다. 이에 비해 한글 표기법은 가로쓰기와 세로쓰기가 자유롭다. 더구나 음절 단위로 모아쓰기 때문에 공간이 좁은 안내 표지판이나, 도로 교통 표지판에서는 아주 적당하다. 위 <그림 3>은 이것을 잘 나타내 준다. 곧 같은 공간에 한글과 로마자 표기에 의한 공간의 활용도를 보면 한글은 가로쓰기와 세로쓰기가 가능하나, 로마자는 세로쓰기는 불가능하고, 겨우 비스듬히 쓸 수 있다. 그리고 글자에 대한 인식도는 한글은 빠르고 쉽게 파악할 수 있으나, 로마자는 자세히 보지 않으면 인식이 어렵다. 이것은 한글이 가지고 있는 공간 활용도와 인식도가 로마자보다 높다는 것을 나타낸다.
일본 문자와 표기법은 세계에서 가장 복잡하다. 일본 문자는 가타카나·와 히라가나가 있고, 탁음(유성음)을 표기하거나, 반탁음(경음)을 표기할 때는 보조 기호까지 사용한다. 더구나 우리의 일반 문자 생활에서는 한자를 거의 사용하지 않아도 되지만, 일본의 표기법에서는 한자를 사용하지 않는다는 것은 거의 불가능하다. 그것은 일본어도 우리와 마찬가지로 한자어가 많으나, 일본어는 모음 수가 적고, 음절 구조가 단순하여 뜻은 다르고, 발음이 같은 한자어가 너무 많다. 예를 들면 /sai/라는 발음에 ‘才(재), 賽(새), 采(채), 際(제), 最(최), 歲(세), 在(재)’ 등이 있고, /sankai/라는 발음에 ‘山海(산해), 山塊(산괴), 參會(참회), 散會(산회), 散開(산개)’ 등이 있다. 그러므로 이것들을 한자로 표기하지 않으면 그 뜻을 알 수 없다. 일본어 표기법에서 한자를 사용할 수밖에 없는 또 다른 이유는 일본어의 음절 구조에 있다. 곧 일본어는 기본적으로 개음절어이므로 종성이 없다. 따라서 본래 한자어의 종성이 다음 음절로 되기 때문에 종성이 있는 1음절의 한자어가 일본어에서는 2음절로 된다. 이를 히라가나로 표기하면 지면이 배로 늘어난다. 더구나 일본어는 한자를 읽는 방법이 훈(訓)으로 읽거나 음(音으)로 읽는 두 가지인데, 음뿐만 아니라 훈으로 읽어도 보통 한 자에 2음절이므로 이 또한 한자로 표기하지 않고, 히라가나로 표기하면 두 배로 늘어난다. 예를 들면, ‘규슈’에 있는 지명 ‘熊本’를 히라가나로 표기하면 ‘くまもと’[구마모토]로 네 음절의 글자로 늘어나고, 일본 수상의 성이 ‘小泉’인데 이를 히라가나로 표기하면 ‘ごいずみ’[고이즈미]의 네 음절의 글자로 늘어난다. 그러므로 그들은 뜻을 구별하기 위해서도, 지면의 경제성을 위해서도, 뜻을 나타내는 의미부(어간)는 한자로 표기할 수밖에 없다. 한자로 표기하더라도 고유 명사일 경우, 이를 한자의 훈으로 읽어야 할지, 음으로 읽어야 할지 모르기 때문에 한자의 위에다 첨자로 그 음을 표기하여야 한다. 또한 문자입력기에서 한자를 찾기 위해서는 우리와 같이 새로운 입력키를 눌러야 하는데, 워낙 같은 발음이 많으므로, 찾는 데 시간이 오래 걸린다. 그러므로 일본어 표기법은 세계에서 가장 복잡한 체계라 할 수 있다. 한자를 사용하는 중국의 표기법은 문자 생활에 있어 매우 어려움이 많았다. 그것은 한자의 수가 워낙 많고, 부수와 획수가 복잡하기 짝이 없고, 한자들 간에 문자적 관련성이 적었기 때문이다. 그래서 중국이 공산화되자 가장 먼저 착수한 것이 문자 개혁이었다. 몇 차례의 문자 개혁을 통해 지금의 간자체가 일반화되었지만, 앞서 3장에서도 언급을 한 것처럼, 문자는 크게 세 가지 부분에서 개혁을 하였다. 첫째는 수만 자나 되는 한자를 줄이기 위해서 뜻은 다르더라도 같은 소리가 나는 한자를 같이 사용하였다. 예를 들면 复(復, 複, 覆), 台(臺, 檯, 颱)로 같이 사용하였다. 둘째는 글자체를 간략화하기 위해 부수와 편방을 간단하게 하였다. 예를 들면 幾(几), 賓(宾), 發(发), 龍(龙) 등으로 사용하였다. 셋째는 획수를 줄이기 위해 간략화하였다. 예를 들면, 導(导), 廳(厅), 農(农), 蘭(兰), 漢(汉), 積(积), 術(术), 書(书)등으로 사용하였다. 이러한 간자체는 관습적인 약자도 있었지만, 혁명에 가까운 개혁이었다. 한때 한·중·일 세 나라가 공통된 한자를 설정하자는 국제회의도 있었으나, 중국인 자신들에게는 생존의 문제와 관련되어 전혀 고칠 마음이 없었다. 그러나 이러한 개혁도 실제 생활에서는, 간자체로 고치다 보니 같은 문자가 생기고, 어디까지 바꾸어야 하는지 등의 문제가 있어 몇 차례 수정을 하였다.20) 한때, 청 말의 실권자인 원세개가 문자 개혁을 하기 위해 우리의 한글을 가져다 사용하려고도 했으나, 망한 나라의 문자를 사용하기에는 문제가 있다 하여 그만두었다는 얘기도 전한다. 오랜 과정을 거쳐 문자 개혁을 했으나, 이것을 기계화하는 데는 문제가 많았다. 한자를 타자로 치려면 수많은 부수와 획을 자판에 올려야 하는데, 이것은 불가능한 일이었다. 중국의 한자도 결국은 문자입력기(워드 프로세서)에 의해 기계화가 가능하였던 것이다. 그러나 이것도, 어떤 문자를 사용하여 어떤 순서로 검색하느냐가 문제였다. 그래서 도입한 것이 한어병음법(漢語倂音法)이다. 이것은 한자의 발음을 로마자로 표기하는 것이다. 그래서 이 로마자의 순서로 문자입력기에 입력하면 그에 따른 한자가 나온다. 그런데 우리는 성조가 없기 때문에 해당하는 문자를 찾으면 되지만, 중국어에서는 성조가 있기 때문에 성조별로 또 다시 배열을 해야 한다. 그리고 같은 성조 안에 배열된 한자를 다시 찾아서 입력해야 하는 것이다. 한어병음법 이전에는 찾으려는 한자의 부수를 알아야 하고, 다시 획수를 알아야 찾을 수 있었지만, 한어병음법 이후로는 발음 부호(한어병음)로 찾으므로 한결 체계화되고 쉬워졌다. 그런데 우리의 일반적인 문자 생활은 한글만으로 거의 가능하므로, 문자 입력기에서 간혹 한자를 사용할 필요가 있을 때에만 특수키를 사용하여 한자를 입력하면 된다. 그러나 중국인들의 문자 생활은 모두 한자로 하여야 하기 때문에 특수키를 매번 눌러야 하고, 그것도 해당하는 성조를 찾기 위해 두 번 이상을 눌러야 하므로, 그에 따른 시간을 우리보다 배로 들여야만 입력이 가능하다. 그러니 우리에 비하면 중국인들의 문자 생활은 복잡하기 짝이 없다. 그들은 휴대 전화로 문자를 입력하기 위해서도 꼭 같은 과정을 거쳐야 한다. 중국어와 일본어는 음절 구조에서 한국어와 많은 차이가 나고, 모음의 수가 적어 음절 구조가 복잡한 외국어를 표기하기에 아주 어려운 점이 많다. 예를 들면, 영어의 ‘MacDonald’[mækdɔnəld]를 한국어로는 ‘맥도날드’로 표기하지만, 중국어로는 ‘麦当劳’[màidaŋlǎo 마이당라오], 일본어로는 ‘まくどなるど’[makudonaludo 마구도나루도]로 표기한다. 중국어와 일본어로는 음절 수도 다르고 발음에 있어서도 원어와 많은 차이가 난다. 그래도 영어에 가장 가까운 발음과 표기가 한국어와 한글 표기일 것이다. 이것은 중국어와 일본어에 모음 수가 적고, 음절 말에 오는 자음에 제한이 있기 때문이다. 물론 한국어에도 영어처럼 음절 말에 겹자음이 올 수는 없지만, /p, t, k, m, n, ŋ, r /21) 의 일곱 자음이 올 수 있다. 그런데 중국어에는 /n, ŋ/의 둘만이 올 수 있고, 일본어에는 /N/22) 하나밖에 오지 못한다. 그들 언어의 이러한 특성으로 표기에도 제한이 있을 수밖에 없다.23) 그런데 이것은 거꾸로 중국인들에게 모든 외래어를 자국어화하는 장점도 있다. 중국인들은 또한 그들의 한자의 표의성에 표음성을 적당히 섞어 표기하는데, 예를 들면 영어의 ‘mini’ (skirt)를 ‘迷你’[mini; 너를 유혹한다]로 표기하는 재미도 있다. 우스갯소리로 영어의 ‘Coca-Cola’를 미국과 수교하기 전에는 제국주의 산물이라 하여 ‘可苦可辣’(쓰고, 맵다)로 했다가, 수교 후에는 ‘可口可樂’(입이 즐겁다)로 바꾸었다는 일화도 있다. 우리가 사용하는 외래어에서 중국어와 일본어에서 건너온 한자어가 많다. 중국서 들어온 근대 용어 한자어 가운데, 유명한 것으로 양주동 선생의 일화에 전하는 ‘기하’(幾何)라는 용어가 있다. ‘기하’는 수학의 한 분야인데, 그 뜻을 우리말로 풀이하면 ‘몇 어찌’라는 말인데, 이 말과 수학의 한 분야와 어떤 관련성이 있는지 알기는 어렵다. 알고 보니, 영어의 ‘geometry’에서 ‘geo’만 따서 중국어로 음사한 것이 ‘幾何’이었다(幾何의 중국어 발음이 지허[jihe]이므로). 우리는 그것도 모르고 그냥 우리 한자 발음으로 [기하]라 부르니 그 관련성을 알기가 어려운 것이다. 중국을 통해 들어온 인도 불교 용어의 대부분이 이렇게 들어오기도 하였다. 일본어에서 들어온 ‘함수’(函數)라는 말과 수학의 ‘function’이라는 말도 일본 학자가 개발한 말이라 한다. 곧 암상자에 어떤 것을 입력하였더니 어떤 것이 출력되는 관계로 파악하여 이를 ‘함수’(函數)로 번역하였다는 것이다. 현재 우리가 사용하는 서양식 외래어가 너무 많은 것도 따지고 보면, 우리의 음절 구조가 중국어나 일본어처럼 단순하지 않고, 모음의 수가 많아 외국어를 그대로 전사하기에 편리하고, 또한 한글이 음소 문자라 소리대로 표기하기가 편리하기 때문일 것이다. 우리가 일상으로 외국어를 자주 쓰고, 표기에도 자주 사용하는 이유도 따지고 보면, 우리말의 음절 구조가 일본어와 중국어에 비해 서양어를 나타내기에 편리하고, 또한 이를 표기하기도 편리한 문자 때문이라는 이유도 있을 것이다. 6. 맺음말 오늘날 우리의 국력과 경제력이 국민들의 피땀 어린 노력의 결과임은 부인할 수 없지만, 우리의 문자인 한글의 과학성과 체계성도 큰 역할을 하였다. 더욱이 21세기 정보화 시대를 맞아 우리가 세계적인 수준으로 정보화가 진척된 것은 우리 문자와 표기법의 우수성이 분명히 한몫을 하였다.우리 문자인 한글의 우수성과 표기법의 우수성은 문자 발달사에서 그리고 언어학자들의 주장에서도 증명이 되었고, 또한 우리의 문자 생활이 다른 어떤 나라의 문자생활보다도 편리하다는 것에서도 확인되었다. 그러므로 이러한 문자의 우수성과 표기법의 우수성을 바탕으로 우리의 정보화 수준을 한층 발전시킬 수 있었다는 것은 분명한 것이다. 앞으로 이러한 정보화의 수준을 더욱 발전시키려면, 우리의 문자체와 표기를 다양화할 필요가 있다. 곧 인쇄술이나, 거리의 간판과, 표지판의 인식률을 높이기 위해 다양한 서체와 표기를 개발할 필요가 있다. 아울러 우리의 국력과 경제력을 바탕으로 ‘한류’라는 이름으로 우리 문화가 아시아를 중심으로 세계 속으로 퍼져 나가고 있는 이 때, 우리는 우리 문화의 정수인 우리말과 글에 대한 관심과 애정을 갖고서 언어생활과 문자 생활을 발전시키고 그 우수성을 세계에 알려야 할 것이다. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||